最新版では不要です。

MioTTS をローカルマシンにインストールする手順を紹介します。
Pythonをインストールします。バージョン 3.12 が推奨されているようです。
インストール手順はこちらの記事を参照してください。
Gitをインストールします。インストール手順はこちらの記事を参照してください。
Ollamaをインストールします。インストール手順はこちらの記事を参照してください。
MioTTS のプログラムをGitHubから取得します。次のコマンドを実行します。
cd (MioTTSを配置するディレクトリ)
git clone https://github.com/Aratako/MioTTS-Inference.git
今回はvenvを利用して仮想環境を作成します。
cd MioTTS-Inference
python -m venv .venv
または
cd MioTTS-Inference
(Pythonの配置パス)\python.exe -m venv .venv
以下のコマンドを実行して、ライブラリをインストールします。
.venv\Scripts\Activate.bat
python.exe -m pip install --upgrade pip
pip install uv
Git,Ollamaにパスが通っていない環境の場合には、Activate.batを編集します。
set "PATH=%VIRTUAL_ENV%\Scripts;%PATH%"
set "PATH=%VIRTUAL_ENV%\Scripts;%PATH%;(Git.exeが配置されているパス);(Ollama.exeが配置されているパス)"
変更後に再度Activate.bat を実行し、venv環境で以下のコマンドを実行します。
uv sync
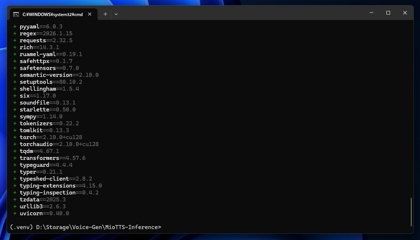
syncの実行結果は下図です。
以下のコマンドを実行し、起動できるかを確認します。
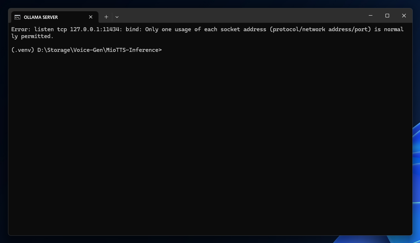
ollama serve
エラーが表示されていますが、こちらはすでに起動済みの状態です。
ollama run hf.co/Aratako/MioTTS-GGUF:MioTTS-2.6B-BF16.gguf
初回起動時にはモデルのダウンロードが実行されます。今回は2.6Bのモデルを利用しています。
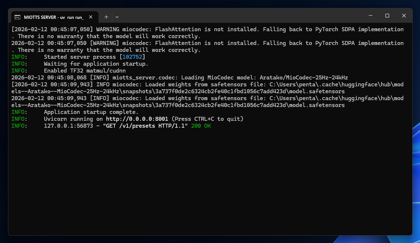
uv run run_server.py --llm-base-url http://localhost:11434/v1
python run_gradio.py
サーバーとWebUIをまとめて起動できるように、以下のバッチファイルをMioTTSの配置ディレクトリ(run_gradio.pyのあるディレクトリ)に作成します。
いったんCPUモードで起動します。
call .venv\Scripts\activate.bat
start "OLLAMA SERVER" cmd /k ollama serve
timeout /t 3 /nobreak > nul
start "OLLAMA MODEL" cmd /k ^
ollama run hf.co/Aratako/MioTTS-GGUF:MioTTS-2.6B-BF16.gguf
timeout /t 5 /nobreak > nul
start "MIOTTS SERVER" cmd /k ^
uv run run_server.py --llm-base-url http://localhost:11434/v1 --device cpu
timeout /t 5 /nobreak > nul
start "MIOTTS WEBUI" cmd /k python run_gradio.py
作成したバッチファイルを実行します。
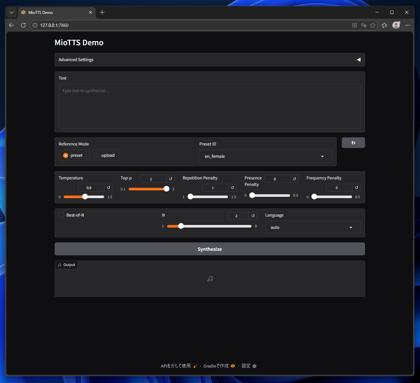
GradioのURL(デフォルトの場合は、http://127.0.0.1:7860/)にアクセスします。
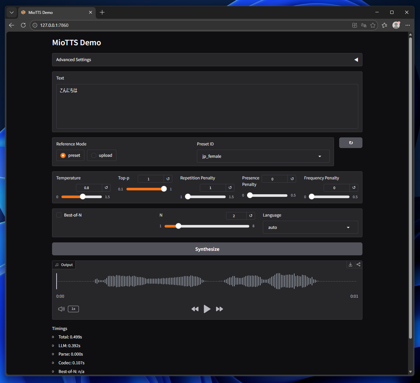
下図のページが表示されます。
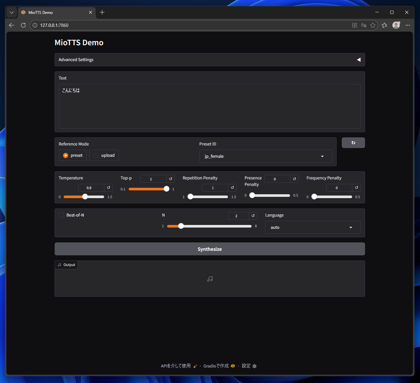
Textのエリアに音声合成したいセリフのテキストを入力します。今回は「こんにちは」を入力しています。
[Preset ID]を"jp_female"に設定し、[Synthesize]ボタンをクリックします。
音声が合成されると、ページ下部に生成された音声の波形が表示され、再生できる状態になります。
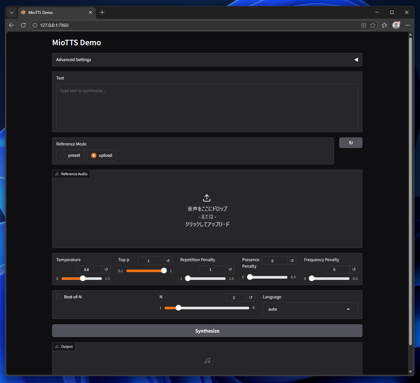
参照音声を指定する場合は、[Reference Mode]の"upload"ラジオボタンをクリックして選択します。
[音声をここにドロップ]のエリアに参照したい音声ファイルをドロップするか、枠をクリックしてファイルを選択してアップロードします。
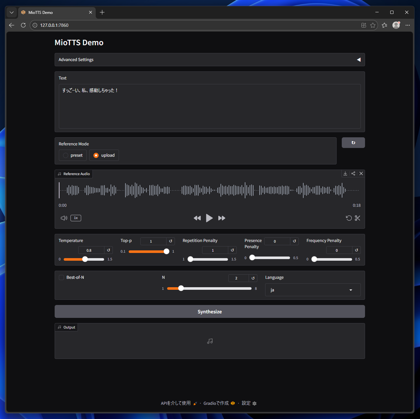
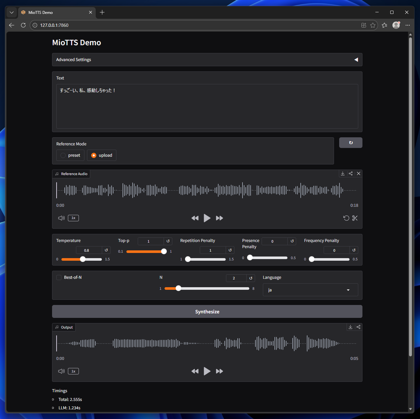
Textのエリアに音声合成したいセリフのテキストを入力し、[Synthesize]ボタンをクリックします。
音声が合成されると、ページ下部に生成された音声の波形が表示され、再生できる状態になります。
def synthesize(
self,
tokens: list[int] | torch.Tensor,
reference_waveform: torch.Tensor | None = None,
global_embedding: torch.Tensor | None = None,
target_audio_length: int | None = None,
) -> torch.Tensor:
if reference_waveform is None and global_embedding is None:
raise ValueError("Either reference_waveform or global_embedding is required.")
# Extract global embedding from reference waveform if provided
if reference_waveform is not None:
ref_features = self.codec.encode(reference_waveform, return_content=False, return_global=True)
global_embedding = ref_features.global_embedding
if isinstance(tokens, list):
tokens = torch.tensor(tokens, dtype=torch.long, device=_codec_device(self.codec))
elif isinstance(tokens, torch.Tensor) and tokens.dtype != torch.long:
tokens = tokens.long()
return self.codec.decode(
global_embedding=global_embedding,
content_token_indices=tokens,
target_audio_length=target_audio_length,
)
def synthesize(
self,
tokens: list[int] | torch.Tensor,
reference_waveform: torch.Tensor | None = None,
global_embedding: torch.Tensor | None = None,
target_audio_length: int | None = None,
) -> torch.Tensor:
if reference_waveform is None and global_embedding is None:
raise ValueError("Either reference_waveform or global_embedding is required.")
device = _codec_device(self.codec)
# Extract global embedding from reference waveform if provided
if reference_waveform is not None:
reference_waveform = reference_waveform.to(device=device, dtype=torch.float32)
ref_features = self.codec.encode(reference_waveform, return_content=False, return_global=True)
global_embedding = ref_features.global_embedding
if isinstance(tokens, list):
tokens = torch.tensor(tokens, dtype=torch.long, device=device)
elif isinstance(tokens, torch.Tensor) and tokens.dtype != torch.long:
tokens = tokens.long()
return self.codec.decode(
global_embedding=global_embedding,
content_token_indices=tokens,
target_audio_length=target_audio_length,
)
def synthesize_batch(
self,
tokens_list: list[list[int]] | list[torch.Tensor],
reference_waveform: torch.Tensor | None = None,
global_embedding: torch.Tensor | None = None,
target_audio_lengths: list[int] | None = None,
padding_token_idx: int = 0,
) -> tuple[torch.Tensor, torch.Tensor]:
if reference_waveform is None and global_embedding is None:
raise ValueError("Either reference_waveform or global_embedding is required.")
logger.debug("Synthesize batch: items=%d", len(tokens_list))
device = _codec_device(self.codec)
# Extract global embedding from reference waveform if provided
if reference_waveform is not None:
ref_features = self.codec.encode(reference_waveform, return_content=False, return_global=True)
global_embedding = ref_features.global_embedding
def synthesize_batch(
self,
tokens_list: list[list[int]] | list[torch.Tensor],
reference_waveform: torch.Tensor | None = None,
global_embedding: torch.Tensor | None = None,
target_audio_lengths: list[int] | None = None,
padding_token_idx: int = 0,
) -> tuple[torch.Tensor, torch.Tensor]:
if reference_waveform is None and global_embedding is None:
raise ValueError("Either reference_waveform or global_embedding is required.")
logger.debug("Synthesize batch: items=%d", len(tokens_list))
device = _codec_device(self.codec)
# Extract global embedding from reference waveform if provided
if reference_waveform is not None:
reference_waveform = reference_waveform.to(device=device, dtype=torch.float32)
ref_features = self.codec.encode(reference_waveform, return_content=False, return_global=True)
global_embedding = ref_features.global_embedding
--device cuda に変更します。call .venv\Scripts\activate.bat
start "OLLAMA SERVER" cmd /k ollama serve
timeout /t 3 /nobreak > nul
start "OLLAMA MODEL" cmd /k ^
ollama run hf.co/Aratako/MioTTS-GGUF:MioTTS-2.6B-BF16.gguf
timeout /t 5 /nobreak > nul
start "MIOTTS SERVER" cmd /k ^
uv run run_server.py --llm-base-url http://localhost:11434/v1 --device cuda
timeout /t 5 /nobreak > nul
start "MIOTTS WEBUI" cmd /k python run_gradio.py
Best-of-Nを利用する場合は、run_server.py のオプションに --best-of-n-enabled を追加します。
初回実行時にモデルのダウンロードが実行されるため、初回の実行には失敗する場合があります。モデルのダウンロード完了後に再度実行します。
call .venv\Scripts\activate.bat
start "OLLAMA SERVER" cmd /k ollama serve
timeout /t 3 /nobreak > nul
start "OLLAMA MODEL" cmd /k ^
ollama run hf.co/Aratako/MioTTS-GGUF:MioTTS-2.6B-BF16.gguf
timeout /t 5 /nobreak > nul
start "MIOTTS SERVER" cmd /k ^
uv run run_server.py --llm-base-url http://localhost:11434/v1 --best-of-n-enabled --device cuda
timeout /t 5 /nobreak > nul
start "MIOTTS WEBUI" cmd /k python run_gradio.py
生成結果は以下の動画で紹介しています。
調整をしていない生成結果そのままの音声です。
MioTTSと T5Gemma-TTS, Style-Bert-VITS2, Qwen3-TTS で比較してみます。比較結果は以下の動画です。


