情報によると、音声の生成に時間がかかっても良いのであれば、"Qwen3-TTS" より、"T5Gemma-TTS" のほうが日本語の
イントネーションが自然だという話を聞きました。自分のPCで利用したいのですが、どのようにセットアップすればよいですか?
この記事で紹介しているサブプロセスで実行する方式は毎回モデルをロードするため、生成処理に時間がかかる点に注意が必要です。

T5Gemma-TTS のインストール手順を紹介します。
Pythonをインストールします。今回はバージョン 3.12 を利用しています。
インストール手順はこちらの記事を参照してください。
Gitをインストールします。インストール手順はこちらの記事を参照してください。
T5Gemma-TTSのプログラムをGitHubから取得します。次のコマンドを実行します。
cd (T5Gemma-TTSを配置するディレクトリ)
git clone https://github.com/Aratako/T5Gemma-TTS.git
仮想環境を作成します。
cd T5Gemma-TTS
python -m venv .venv
python -m pip install -U pip
.venv\Scripts\Activate.bat
pip install -r requirements.txt
利用しているGPUに合わせてTorchを入れ替えます。以下はRTX 5000 シリーズ(Blackwell)の場合の例です。
pip uninstall torch torchvision torchaudio -y
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
bitsandbytes をWindows版に入れ替えます。この処理は無くても動作するはずです。
pip uninstall bitsandbytes -y
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.1-py3-none-win_amd64.whl
以上でインストールは完了です。次のコマンドを実行して音声合成ができるかを確認します。
python inference_commandline_hf.py --model_dir Aratako/T5Gemma-TTS-2b-2b --target_text "こんにちは、これは音声合成のテストです。" --target_duration 5.0
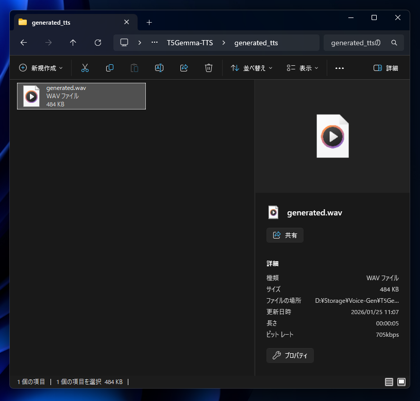
正常に実行できると、(T5Gemma-TTSの配置するディレクトリ)\T5Gemma-TTS\generated_tts フォルダ内に generated.wav ファイルが生成できます。
GradioのWebUIもありますが、Windowsではうまく動作しないため、サブプロセスで実行するWebUIを用意します。
DockerやWSL2を利用する方法が正攻法ですが、セットアップや運用に手間がかかるため、今回は非効率でもネイティブWindowsで動作する方法を導入します。
(T5Gemma-TTSの配置するディレクトリ)\T5Gemma-TTS に inference_gradio_subprocess.py ファイルを作成します。以下のコードを記述します。
"""
Gradio demo for HF-format T5GemmaVoice checkpoints.
Usage:
python inference_gradio.py --model_dir ./t5gemma_voice_hf --port 7860
"""
import argparse
import os
import subprocess
import sys
import tempfile
from pathlib import Path
import gradio as gr
import numpy as np
import soundfile as sf
def run_inference_subprocess(
model_dir: str,
target_text: str,
target_duration: float = None,
reference_speech: str = None,
reference_text: str = None,
top_k: int = 30,
top_p: float = 0.9,
min_p: float = 0.0,
temperature: float = 0.8,
seed: int = None,
) -> tuple:
"""
subprocess で inference_commandline_hf.py を呼び出して音声を生成。
Returns: (sample_rate, waveform)
"""
with tempfile.TemporaryDirectory() as tmpdir:
cmd = [
sys.executable,
str(Path(__file__).parent / "inference_commandline_hf.py"),
"--model_dir", model_dir,
"--target_text", target_text,
"--output_dir", tmpdir,
"--top_k", str(top_k),
"--top_p", str(top_p),
"--min_p", str(min_p),
"--temperature", str(temperature),
]
if target_duration is not None:
cmd.extend(["--target_duration", str(target_duration)])
if reference_speech is not None and reference_speech.strip():
cmd.extend(["--reference_speech", reference_speech])
if reference_text is not None and reference_text.strip():
cmd.extend(["--reference_text", reference_text])
if seed is not None:
cmd.extend(["--seed", str(seed)])
print(f"[Debug] Running subprocess: {' '.join(cmd)}")
result = subprocess.run(
cmd,
capture_output=True,
text=True,
encoding="utf-8",
)
if result.returncode != 0:
print(f"[Error] subprocess failed:\n{result.stderr}")
raise RuntimeError(f"Inference failed: {result.stderr}")
print(result.stdout)
# 生成されたファイルを読み込む
wav_path = os.path.join(tmpdir, "generated.wav")
if not os.path.exists(wav_path):
raise FileNotFoundError(f"Generated audio not found: {wav_path}")
waveform, sample_rate = sf.read(wav_path)
return (sample_rate, waveform.astype(np.float32))
def build_demo(model_dir: str, server_port: int, share: bool):
description = (
"Reference speech is optional. If provided without reference text, Whisper (large-v3-turbo) "
"will auto-transcribe and use it as the prompt text.\n\n"
"**Note**: This version uses subprocess for inference (slower startup per request but more stable)."
)
with gr.Blocks() as demo:
gr.Markdown("## T5Gemma-TTS (HF) - Subprocess Mode")
gr.Markdown(description)
with gr.Row():
reference_speech_input = gr.Audio(
label="Reference Speech (optional)",
type="filepath",
)
reference_text_box = gr.Textbox(
label="Reference Text (optional, leave blank to auto-transcribe)",
lines=2,
)
target_text_box = gr.Textbox(
label="Target Text",
value="こんにちは、私はAIです。これは音声合成のテストです。",
lines=3,
)
with gr.Row():
target_duration_box = gr.Textbox(
label="Target Duration (seconds, optional)",
value="",
placeholder="Leave blank for auto estimate",
)
seed_box = gr.Textbox(
label="Random Seed (optional)",
value="",
placeholder="Leave blank for random",
)
with gr.Row():
top_k_box = gr.Slider(label="top_k", minimum=0, maximum=100, step=1, value=30)
top_p_box = gr.Slider(label="top_p", minimum=0.1, maximum=1.0, step=0.05, value=0.9)
min_p_box = gr.Slider(label="min_p (0 = disabled)", minimum=0.0, maximum=1.0, step=0.05, value=0.0)
temperature_box = gr.Slider(label="temperature", minimum=0.1, maximum=2.0, step=0.05, value=0.8)
generate_button = gr.Button("Generate")
output_audio = gr.Audio(label="Generated Audio", type="numpy")
def gradio_inference(
reference_speech,
reference_text,
target_text,
target_duration,
top_k,
top_p,
min_p,
temperature,
seed,
):
dur = float(target_duration) if target_duration and target_duration.strip() else None
seed_val = int(float(seed)) if seed and seed.strip() else None
result = run_inference_subprocess(
model_dir=model_dir,
target_text=target_text,
target_duration=dur,
reference_speech=reference_speech,
reference_text=reference_text,
top_k=int(top_k),
top_p=float(top_p),
min_p=float(min_p),
temperature=float(temperature),
seed=seed_val,
)
return result
generate_button.click(
fn=gradio_inference,
inputs=[
reference_speech_input,
reference_text_box,
target_text_box,
target_duration_box,
top_k_box,
top_p_box,
min_p_box,
temperature_box,
seed_box,
],
outputs=output_audio,
)
demo.launch(server_name="0.0.0.0", server_port=server_port, share=share)
def main():
parser = argparse.ArgumentParser(description="Gradio demo (subprocess mode)")
parser.add_argument("--model_dir", type=str, default="./t5gemma_voice_hf")
parser.add_argument("--port", type=int, default=7860)
parser.add_argument("--share", action="store_true")
args = parser.parse_args()
build_demo(model_dir=args.model_dir, server_port=args.port, share=args.share)
if __name__ == "__main__":
main()
WebUIを起動するためのバッチファイルを作成します。
(T5Gemma-TTSの配置するディレクトリ)\ に webui.bat ファイルを作成します。以下のコードを記述します。
@echo off
call T5Gemma-TTS\.venv\Scripts\activate.bat
python T5Gemma-TTS\inference_gradio_subprocess.py --model_dir Aratako/T5Gemma-TTS-2b-2b --port 7860
バッチファイルを実行します。
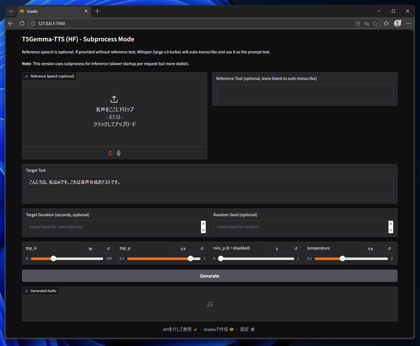
http://127.0.0.1:7860/ にアクセスします。下図のページが表示されます。
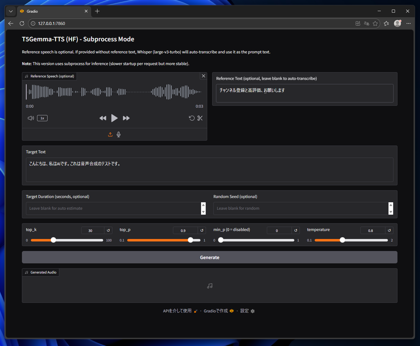
[Reference Speech]に参照する音声ファイルを設定します。また、[Reference Text]にはReference Speechに設定した音声がしゃべっているテキストを設定します。
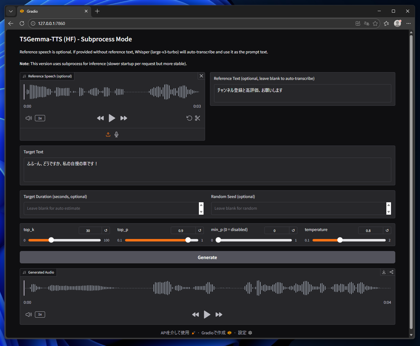
[Target Text]に音声合成でしゃべらせたいテキストを設定します。設定ができたら[Generate]ボタンをクリックします。
音声合成ができると下部の[Generated Audio]の枠にサウンドの波形が表示され、再生できます。
音声の生成結果は以下の動画です。
T5Gemma-TTS と Style-Bert-VITS2, Qwen3-TTS で比較してみます。比較結果は以下の動画です。