Success:すべての前処理が完了しました。ターミナルを確認しておかしいところがないか確認するのをおすすめします。
Style-Bert-VITS2で音声を学習して音声合成モデルを作成する手順を紹介します。
Style-Bert-VITS2で音声データを学習して、別の声質の音声合成のモデルを作成します。
Style-Bert-VITS2をインストールします。
学習元の音声データを準備します。
多くの事例では、「ずんだもん」や「つくよみちゃん」を利用するケースが多いですが、
今回は、「exVOICE 結月ゆかり」のデータでどの程度の学習ができるかを検証します。
exVOICE ではあまり長いセリフがデータとして収録されていないため、狙った通りの結果にはならないかもしれません。
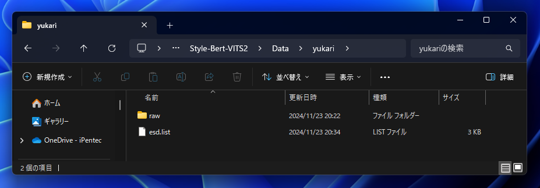
以下のディレクトリを作成します。
(Style-Bert-VITS2の配置ディレクトリ)\Data\yukari
ディレクトリ内に、rawディレクトリと、esd.list ファイルを作成します。
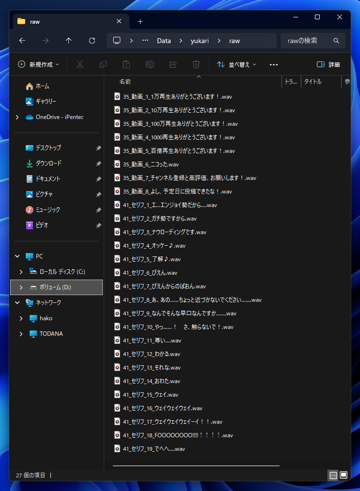
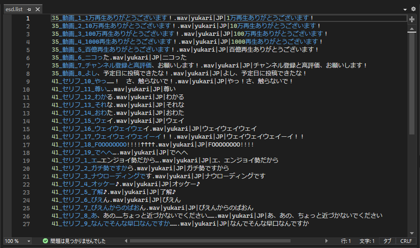
rawディレクトリ内に、音声ファイルを配置します。今回は27ファイルを利用します。
esd.list ファイルには音声ファイル名と、音声でしゃべっているセリフを記述します。
なお、ファイルはUTF-8でエンコードして、「BOMは無し」とします。
35_動画_1_1万再生ありがとうございます!.wav|yukari|JP|1万再生ありがとうございます!
35_動画_2_10万再生ありがとうございます!.wav|yukari|JP|10万再生ありがとうございます!
35_動画_3_100万再生ありがとうございます!.wav|yukari|JP|100万再生ありがとうございます!
35_動画_4_1000再生ありがとうございます!.wav|yukari|JP|1000再生ありがとうございます!
35_動画_5_百億再生ありがとうございます!.wav|yukari|JP|百億再生ありがとうございます!
35_動画_6_ニコった.wav|yukari|JP|ニコった
35_動画_7_チャンネル登録と高評価、お願いします!.wav|yukari|JP|チャンネル登録と高評価、お願いします!
35_動画_8_よし、予定日に投稿できたな!.wav|yukari|JP|よし、予定日に投稿できたな!
41_セリフ_10_やっ……! さ、触らないで!.wav|yukari|JP|やっ!さ、触らないで!
41_セリフ_11_尊い….wav|yukari|JP|尊い
41_セリフ_12_わかる.wav|yukari|JP|わかる
41_セリフ_13_それな.wav|yukari|JP|それな
41_セリフ_14_おわた.wav|yukari|JP|おわた
41_セリフ_15_ウェイ.wav|yukari|JP|ウェイ
41_セリフ_16_ウェイウェイウェイ.wav|yukari|JP|ウェイウェイウェイ
41_セリフ_17_ウェイウェイウェイーイ!!.wav|yukari|JP|ウェイウェイウェイーイ!!
41_セリフ_18_FOOOOOOOO!!!!↑↑↑↑.wav|yukari|JP|FOOOOOOOO!!!!
41_セリフ_19_でへへ….wav|yukari|JP|でへへ
41_セリフ_1_エ…エンジョイ勢だから….wav|yukari|JP|エ、エンジョイ勢だから
41_セリフ_2_ガチ勢ですから.wav|yukari|JP|ガチ勢ですから
41_セリフ_3_ナウローディングです.wav|yukari|JP|ナウローディングです
41_セリフ_4_オッケー♪.wav|yukari|JP|オッケー♪
41_セリフ_5_了解♪.wav|yukari|JP|了解♪
41_セリフ_6_ぴえん.wav|yukari|JP|ぴえん
41_セリフ_7_ぴえんからのぱおん.wav|yukari|JP|ぴえんからのぱおん
41_セリフ_8_あ、あの……ちょっと近づかないでください…….wav|yukari|JP|あ、あの、ちょっと近づかないでください
41_セリフ_9_なんでそんな早口なんですか…….wav|yukari|JP|なんでそんな早口なんですか
Style-Bert-VITS2配置ディレクトリの App.bat ファイルを実行します。
Webブラウザが開きます。下図のページが表示されます。
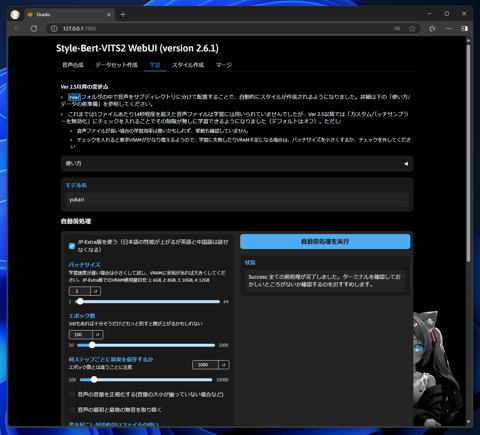
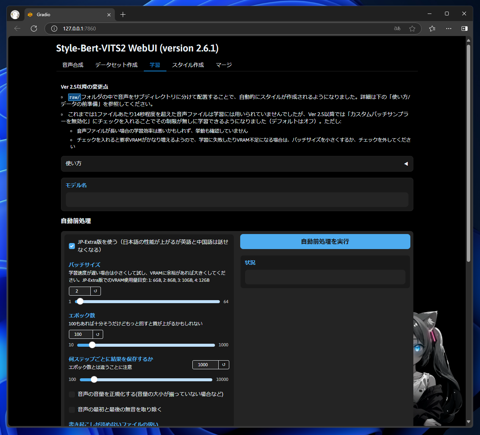
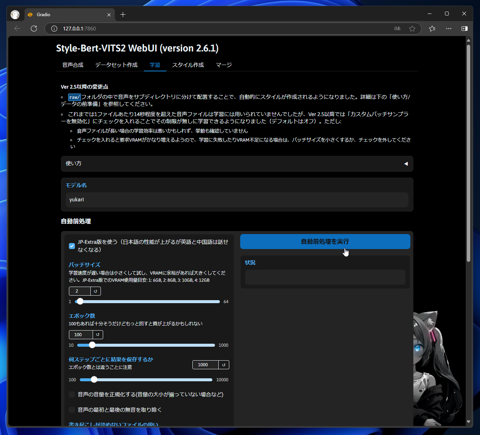
上部のタブの[学習]をクリックします。下図のページが表示されます。
[モデル名]を入力します。モデル名は(Style-Bert-VITS2の配置ディレクトリ)\Data\ 内に作成したディレクトリ名と合わせます。
今回は yukari となります。入力後、ページ右側の[自動前処理を実行]ボタンをクリックします。
前処理が完了するとボタンの下に以下のメッセージが表示されます。
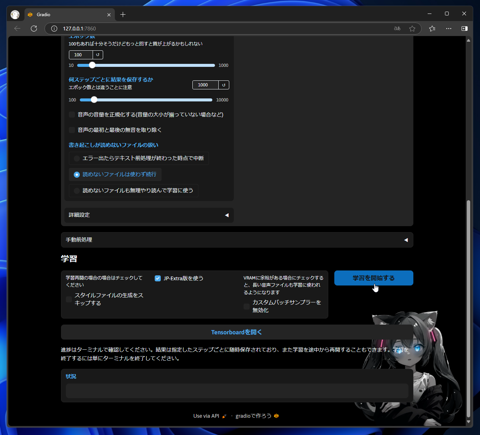
ページを下にスクロールし、[学習を開始する]ボタンをクリックします。
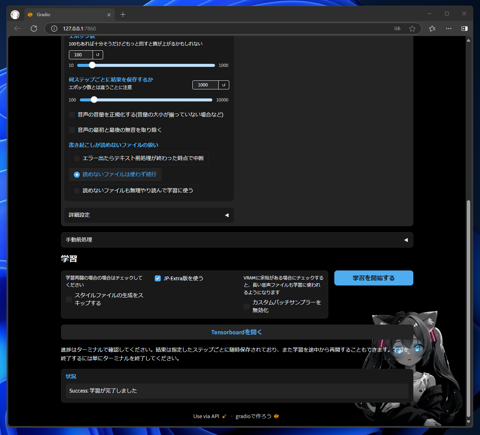
学習(トレーニング)が始まります。学習が完了すると、ページ下部に以下のメッセージが表示されます。
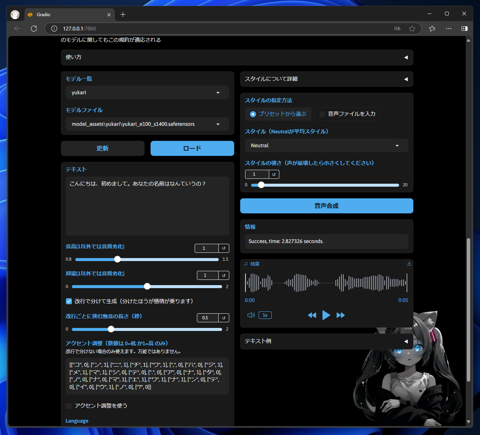
ページ上部の[音声合成]のタブをクリックして選択します。下図のページが表示されます。
ページを下にスクロールします。
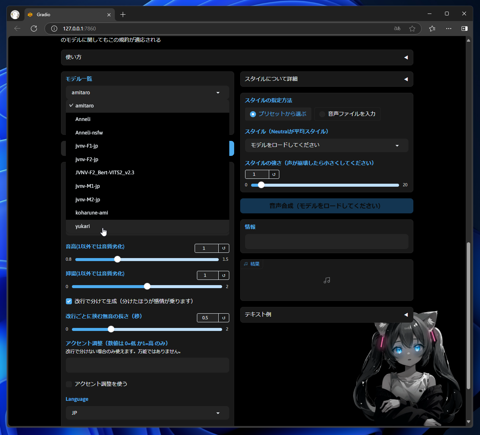
[モデル一覧]をのドロップダウンリストボックスをクリックします。ドロップダウンリストが表示され、先ほど学習したモデルが一覧に表示されています。
クリックして選択します。表示されていない場合は、ドロップダウンリストボックス下部の[更新]ボタンをクリックしてリストを更新します。
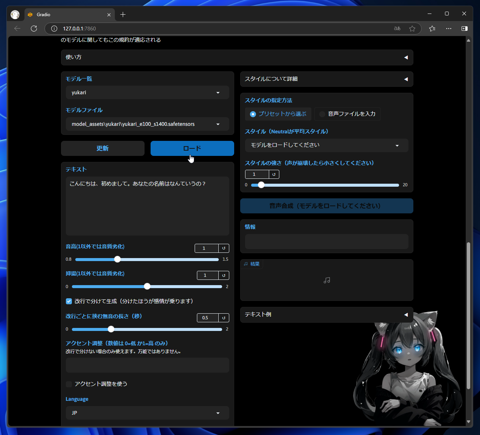
モデルを選択したら、ドロップダウンリストボックス下部の[ロード]ボタンをクリックします。モデルのロードが実行されます。
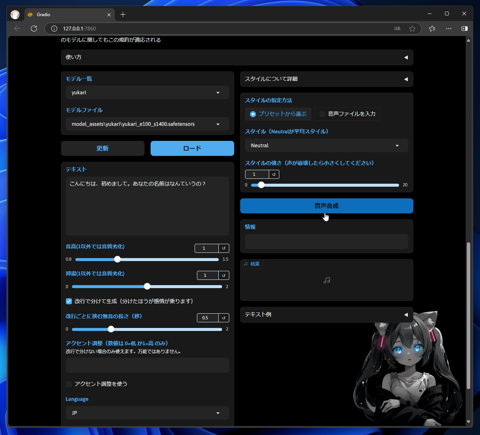
[テキスト]に合成したいセリフのテキストを入力します。今回はデフォルトで入力されているテキストをそのまま利用します。
右側の[音声合成]ボタンをクリックします。
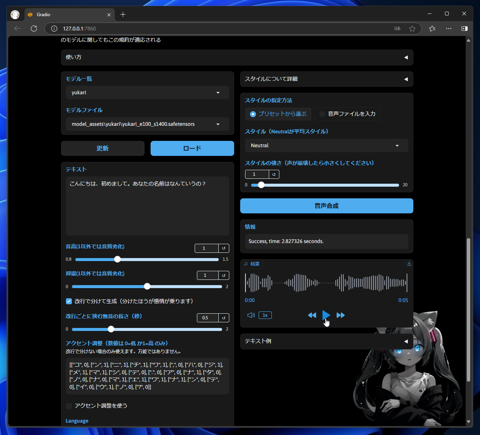
音声が合成され、[音声合成]ボタンの下部に生成された音声の波形が表示されます。
波形の枠の[再生]ボタンをクリックすると、合成された音声を再生できます。
生成された音声は、学習データを反映した声質になっていますが、棒読み感が強い音声です。
感情表現の強いモデルとマージして、棒読み感を改善します。以下の記事を参照してください。
それぞれのモデルの音声合成の結果も以下の記事で紹介しています。