Qwen-Image-Layeredという画像を要素ごとに分離できるモデルが登場したと聞いた。どのような手順で使えるのか教えてほしい。
Separating the character from the background.

Qwen-Image-Layered のインストール手順を紹介します。
ComfyUIをインストールします。最新版である必要があります。
インストール手順はこちらの記事のPortable版のインストールを参照してください
Qwen-Image-Layered をインストールする手順を紹介します。
以下の HuggingFaceのHubから、Qwen-Image-Editのfp8のモデル qwen_image_layered_bf16.safetensors または qwen_image_layered_fp8mixed.safetensors をダウンロードします。
bf16モデルは40.9 GBありますので、VRAM容量の多いGPUを利用していれば選択肢に入ります。
ダウンロードしたモデルを次のディレクトリに配置します。
(ComfyUIの配置ディレクトリ)\models\diffusion_models\
または
(ComfyUIの配置ディレクトリ)\models\diffusion_models\qwen-image-layered\
以下の HuggingFaceのHubから、Qwen-Imageのテキストエンコーダー qwen_2.5_vl_7b_fp8_scaled.safetensors をダウンロードします。(Qwen-Imageと同じです)
ダウンロードしたモデルを次のディレクトリに配置します。
(ComfyUIの配置ディレクトリ)\models\text_encoders\
または
(ComfyUIの配置ディレクトリ)\models\text_encoders\qwen-image\
以下の HuggingFaceのHubから、Qwen-ImageのVAE qwen_image_layered_vae.safetensors をダウンロードします。(Qwen-Imageと同じです)
ダウンロードしたモデルを次のディレクトリに配置します。
(ComfyUIの配置ディレクトリ)\models\vae\
または
(ComfyUIの配置ディレクトリ)\models\vae\qwen-image-layered\
ファイルの配置は以上です。
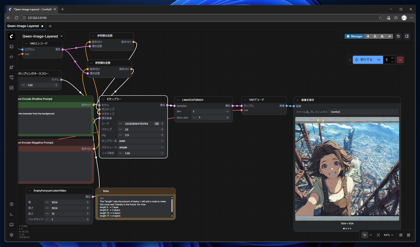
ComfyUIを起動し、以下のワークフローを作成します。
ワークフローのJSONは以下からダウンロードできます。
[拡散モデルを読み込む]ノードのモデルには qwen-image-layered\qwen_image_layered_bf16.safetensors または qwen-image-layered\qwen_image_layered_fp8mixed.safetensors を
設定します。
[CLIPを読み込む]ノードのモデルには qwen-image\qwen_2.5_vl_7b_fp8_scaled.safetensors を設定します。
[VAEを読み込む]ノードのモデルには qwen-image-layered\qwen_image_layered_vae.safetensors を設定します。
[画像を読み込む]ノードに入力画像を設定します。
プロンプトはよくわからないので、いったん以下を入力します。
[実行する]ボタンをクリックして画像生成を実行します。
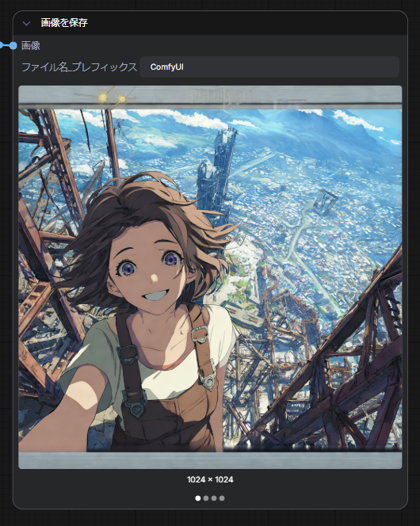
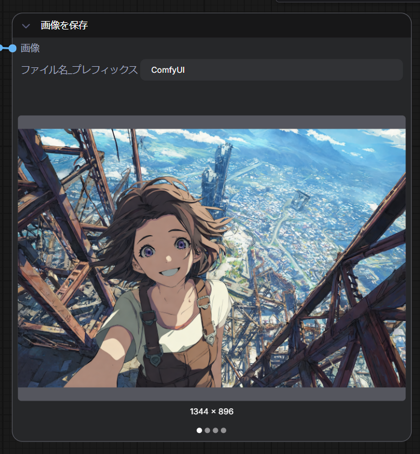
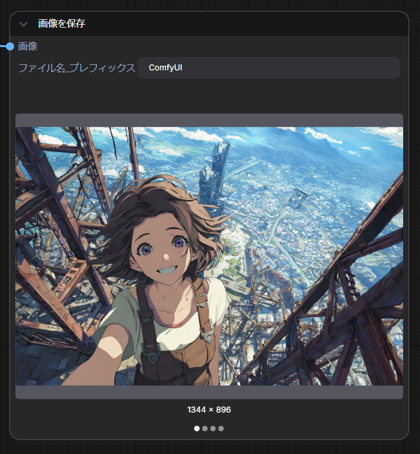
今回の入力画像は下図です。
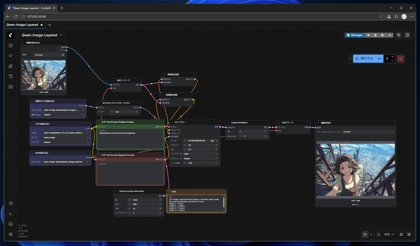
画像生成結果が右側の[画像を保存]ノードに表示されます。正方形で画像が生成されてしまっています。
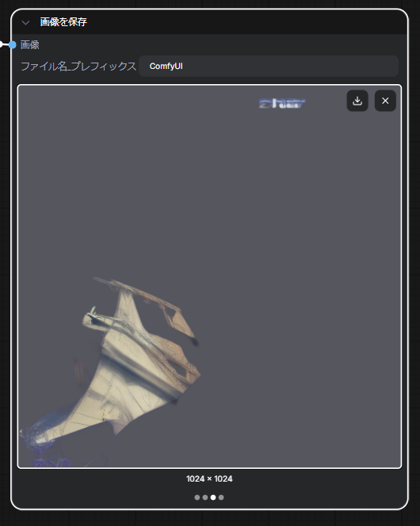
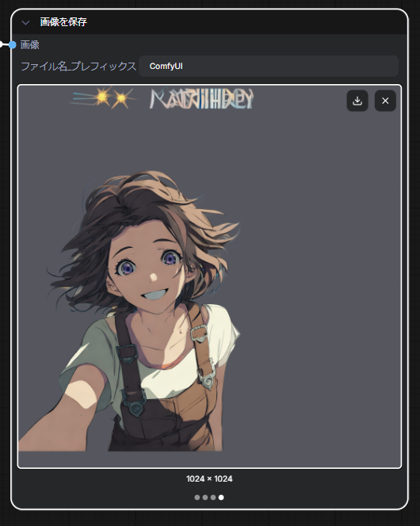
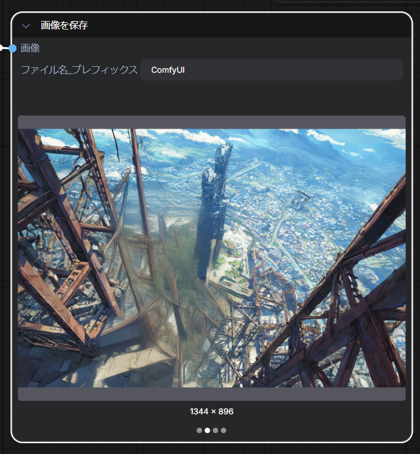
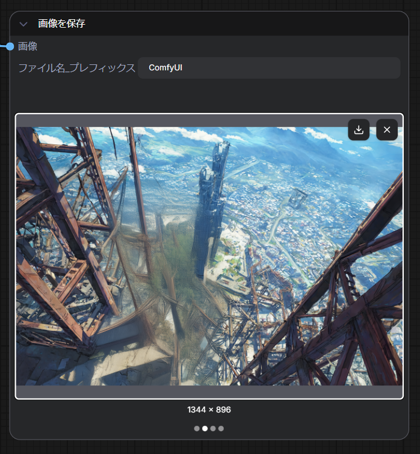
画像生成結果を確認します。4つの画像が保存されており、元画像と要素ごとに分離された3つの画像が保存されています。

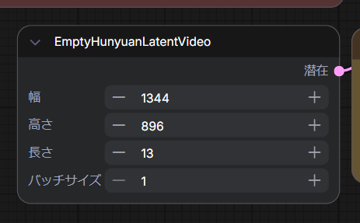
画像サイズを入力画像のサイズと同じにして再度実行します。
[EmptyHunyuanLatentVideo]のノードの[幅]と[高さ]の値を入力画像のサイズと同じピクセル数に設定します。
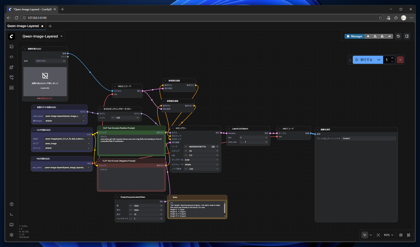
再度実行します。入力画像と同じサイズで生成できました。
背景でキャラクターに隠れた部分はあまりうまく生成できていませんが、この部分の生成に先に設定したプロンプトが使用されるのかもしれません。
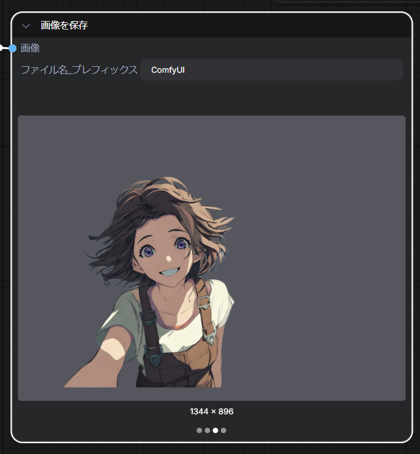
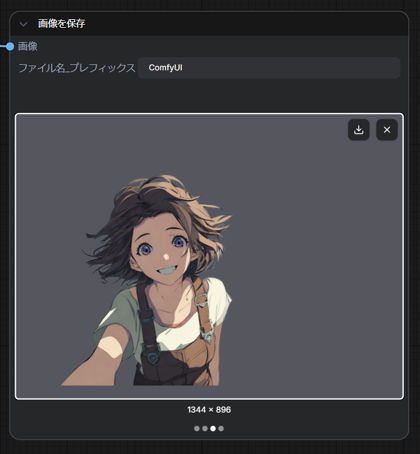
キャラクターの画像は背景が透過された状態で保存されています。緑で背景を塗りつぶしたものが下図です。
きれいに背景が抜けている状態です。


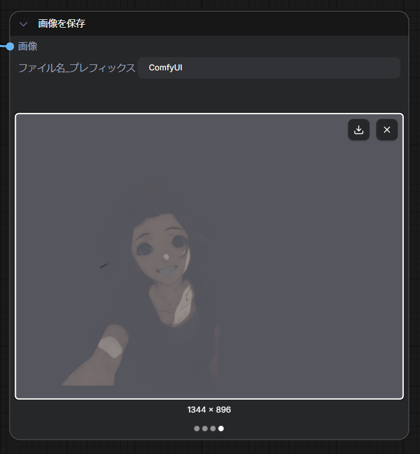
プロンプトを以下に変更して再度実行します。
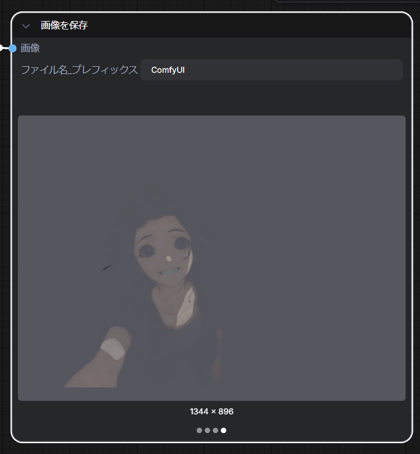
結果は下図です。キャラクターに隠れた背景部分が若干まともになったような気が?
キャラクターが抜き出せることから、BiRefNet for background removalとどちらが性能が良いか比較してみます。
結果は下図です。
"Qwen-Image-Layered"では背景がきれいに抜けており、BiRefNetよりだいぶ良い結果であることがわかります。