Qwen-Imageを利用して画像生成をローカルのPCで実行したい。インストール手順はどのようなものだろうか?
ComfyUIを利用する前提で考えている。

Qwen-Image のインストール手順を紹介します。
ComfyUIをインストールします。最新版である必要があります。
インストール手順はこちらの記事のPortable版のインストールを参照してください
Qwen-Image をインストールする手順を紹介します。
以下の HuggingFaceのHubから、Qwen-Imageのfp8のモデル qwen_image_fp8_e4m3fn.safetensors をダウンロードします。
ダウンロードしたモデルを次のディレクトリに配置します。
(ComfyUIの配置ディレクトリ)\models\diffusion_models\
または
(ComfyUIの配置ディレクトリ)\models\diffusion_models\qwen-image\
以下の HuggingFaceのHubから、Qwen-Imageのテキストエンコーダー qwen_2.5_vl_7b_fp8_scaled.safetensors をダウンロードします。
ダウンロードしたモデルを次のディレクトリに配置します。
(ComfyUIの配置ディレクトリ)\models\text_encoders\
または
(ComfyUIの配置ディレクトリ)\models\text_encoders\qwen-image\
以下の HuggingFaceのHubから、Qwen-ImageのVAE qwen_image_vae.safetensors をダウンロードします。
ダウンロードしたモデルを次のディレクトリに配置します。
(ComfyUIの配置ディレクトリ)\models\vae\
または
(ComfyUIの配置ディレクトリ)\models\vae\qwen-image\
ファイルの配置は以上です。
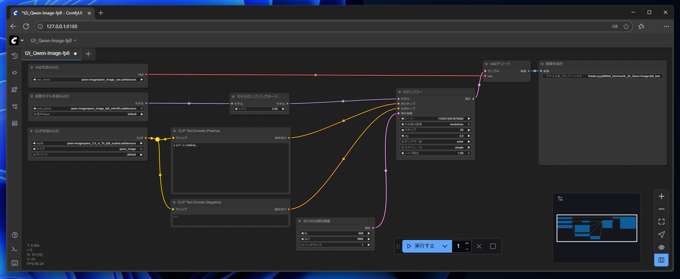
ComfyUIを起動し、以下のワークフローを作成します。
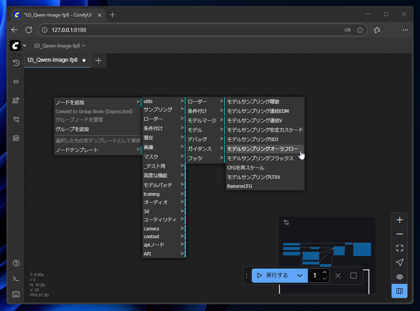
[モデルサンプリングオーラフロー (Model Sampling Auraflow)]のノードは以下のメニューにあります。
[ノードを追加] > [高度な機能] > [モデル] > [モデルサンプリングオーラフロー]
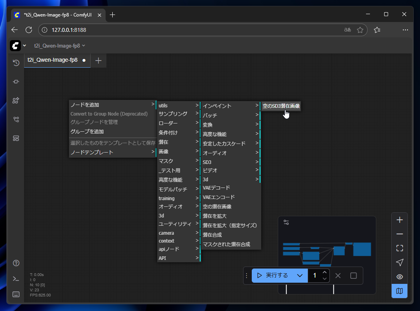
[空のSD3潜在画像]のノードは以下のメニューにあります。
[ノードを追加] > [潜在] > [SD3] > [空のSD3潜在画像]
ワークフローのJSONは以下です。
生成する画像の解像度は以下のサイズが推奨されています。
| 幅 | 高さ | 縦横比 |
|---|---|---|
| 1,328 | 1,328 | 1:1 |
| 1,472 | 1,140 | 4:3 |
| 1,140 | 1,472 | 3:4 |
| 1,664 | 928 | 16:9 |
| 928 | 1,664 | 16:9 |
[CLIP Text Encode (Positive)]のノードのテキストボックスにプロンプトを入力します。
今回は以下のプロンプトを設定します。
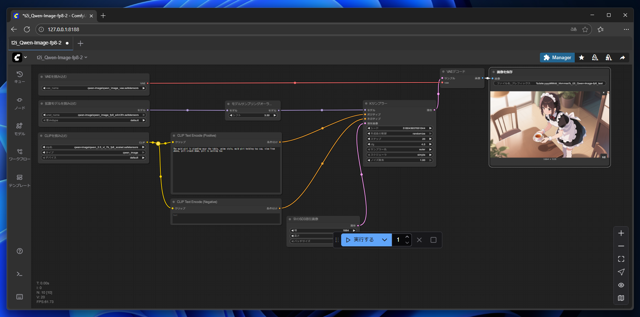
設定ができたら[実行する]ボタンをクリックします。
画像を保存のノードに画像生成結果が表示されます。
生成された画像は下図です。Stable DiffusionやImagenと比較すると以下の点が優れています。