ComfyUI を利用して Stable Diffusion 3.5 で画像を生成する手順を紹介します。
ComfyUIをインストールします。手順はこちらの記事を参照してください。
Stable Diffusion 3.5 のCheckpointとTextEncoderをダウンロードします。
手順はこちらの記事を参照してください。
先の手順でダウンロードしたモデルを配置します。
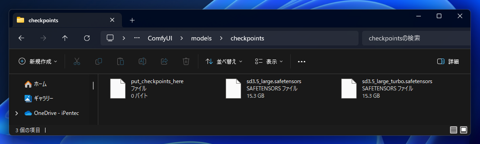
Checkpointのファイルは次のディレクトリに配置します。
(ComfyUIの配置ディレクトリ)\ComfyUI\models\checkpoints
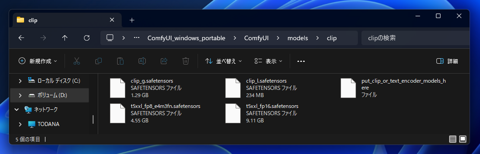
Text Encoderのファイルは次のディレクトリに配置します。
(ComfyUIの配置ディレクトリ)\ComfyUI\models\clip
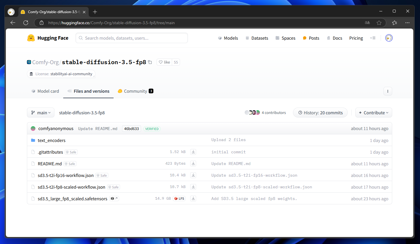
ComfyUIのワークフローをダウンロードします。ComfyUI の Hugging Face (https://huggingface.co/Comfy-Org/stable-diffusion-3.5-fp8/tree/main)に
アクセスします。
sd3.5-t2i-fp16-workflow.json ファイルをダウンロードします。
ワークフローのJSONファイルをダウンロードできました。
ComfyUIを起動します。webブラウザが起動し、下図の画面が表示されます。
[Load]ボタンをクリックします。ファイル選択ダイアログが表示されますので、先にダウンロードしたComfyUIのワークフローのJSONファイルを開きます。
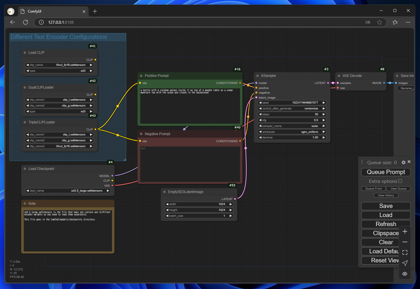
ファイルを開くと、ワークフローが表示されます。
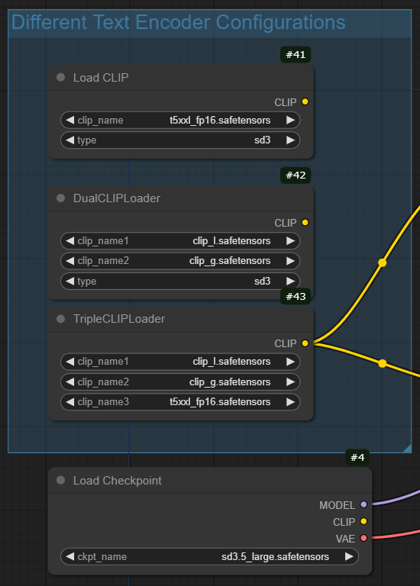
CLIPのロード部分と、Checkpointのロード部分に注目します。"t5xxl_fp16.safetensors" "clip_l.safetensors" "clip_g.safetensors" が表示されています。
各ファイルが存在しているかを再確認します。Checkpointでは、"sd3.5_large.safetensors"が表示されています。こちらもファイルが存在しているかを再確認します。
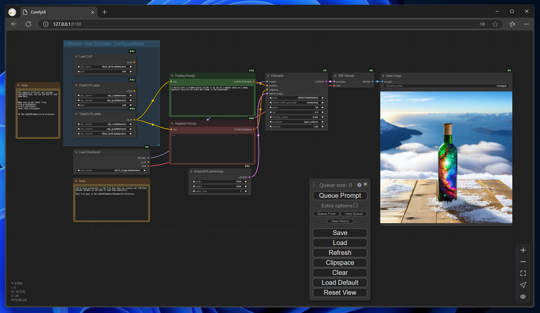
[Queue Prompt]ボタンをクリックして画像を生成します。imagesのノードに生成された画像が表示されます。
Stable Diffusion 3.5で画像生成できました。