音声(音声ファイル)から、しゃべっている内容をテキスト文字に自動で書き起こす手順を紹介します。
スピーチの音声や音声ファイルからしゃべっている内容をテキストにします。OpenAIのWhisperというアプリケーションを利用すると、音声ファイルから
しゃべっている内容をテキストに起こすことができます。
OpenAI Whisper をインストールします。インストール手順はこちらの記事を参照してください。
Whisperの仮想環境に切り替えた後、以下のコマンドを実行します。
whisper --model (モデル) --language (言語) "(音声ファイルのパス)" --output_dir "(出力ディレクトリ)"
--output_dirは省略でき、省略した場合はカレントディレクトリに結果ファイルが出力されます。
モデルは以下が選択できます。
言語はtokenizer.pyファイル内に定義がある値を指定できます。代表的な言語を以下に掲載します。
日本語の文字起こしでPCのスペックに余裕がある場合は、以下のコマンドとなります。
whisper --model large --language Japanese "(音声ファイルのパス)" --output_dir "(出力ディレクトリ)"
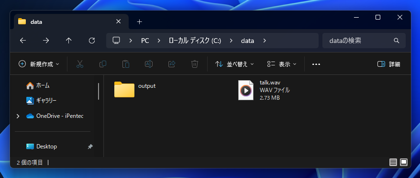
テキストに文字起こししたい音声ファイルを準備します。C:\data\talk.wav ファイルとして配置しました。
また同じディレクトリに outputディレクトリを作成しました。
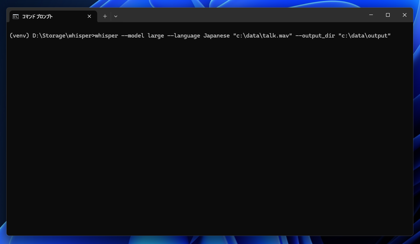
Whisperのインストールディレクトリで仮想環境に切り替え次のコマンドを実行します。
whisper --model large --language Japanese "c:\data\talk.wav" --output_dir "c:\data\output"
ワーニングが表示されますが処理は実行されます。
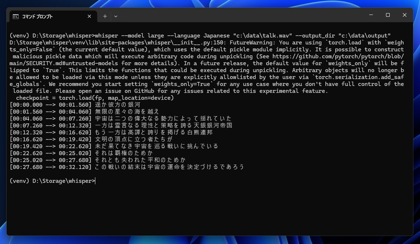
実行が終了すると下図の画面となります。認識できた文字列がコンソールにも表示されています。
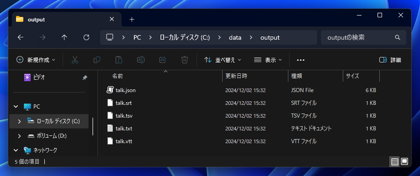
結果は指定した出力ディレクトリにファイルが作成されます。
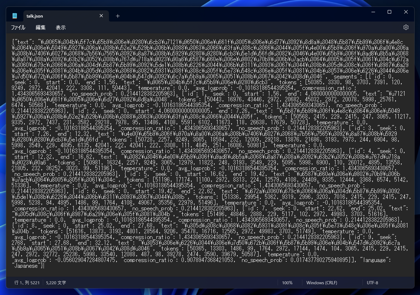
json形式の結果です。
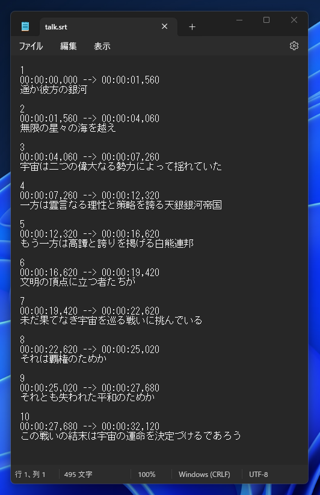
srt形式の結果です。
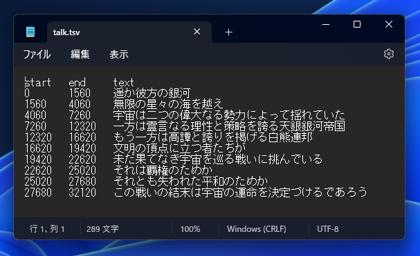
tsv形式の結果です。
txt形式の結果です。
vtt形式の結果です。
今回のデモの音声の台本と書き起こし結果を比較します。
ほとんどあっていますが、固有名詞や普段使わない難しめの単語の検出でうまくいかない部分もあります。
遥か彼方の銀河
無限の星々の海を越え
宇宙は二つの偉大なる勢力によって揺れていた
一方は霊言なる理性と策略を誇る天銀銀河帝国
もう一方は高譚と誇りを掲げる白熊連邦
文明の頂点に立つ者たちが
未だ果てなき宇宙を巡る戦いに挑んでいる
それは覇権のためか
それとも失われた平和のためか
この戦いの結末は宇宙の運命を決定づけるであろう
遥か彼方の銀河。
無限の星々の海を超え、宇宙は二つの偉大なる勢力によって揺れていた。
一方は冷厳なる理性と策略を誇る「ペンギン 銀河帝国」
もう一方は豪胆と誇りを掲げる「シロクマ 連邦」
文明の頂点に立つ者たちが、いまだ果てなき宇宙を巡る戦いに挑んでいる。
それは、覇権のためか、それとも失われた平和のためか——この戦いの結末は、宇宙の運命を決定づけるであろう。
アニメのセリフの音声でテストした結果です。
音はあっているものの、字が違っているケースや2回繰り返してしまう部分があったりしますが、
ほとんど正しく文字起こしできています。
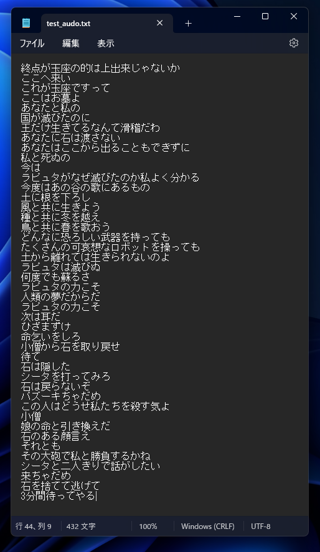
語り調のアニメのセリフを入力した場合の結果です。
https://www.youtube.com/watch?v=ik0-XprwShU
結果は以下です。間違えている部分が若干ありますが、こちらもほとんど問題なく、テキスト起こしできています。
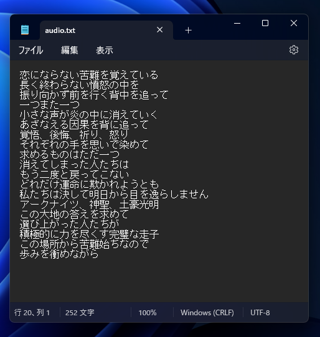
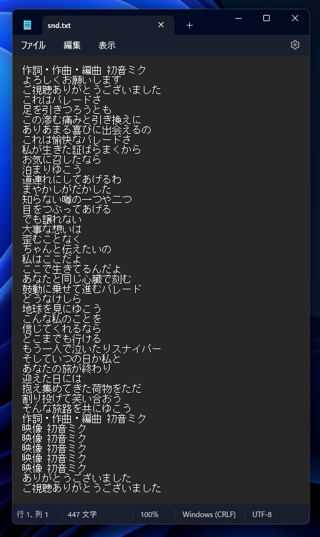
歌を入力した場合の結果です。
https://www.youtube.com/watch?v=szONkV3l21g
歌の場合は検出率がかなり下がり、聞き違いが多く、冒頭に全く違うテキストが検出されたり、
同じセリフを複数回繰り返してテキスト起こししている部分や抜けている部分もあります。
歌に利用するのはあまり適していないようです。