ほかのPCからリクエストして、LLMの結果を取得できるようなサーバーを用意したいです。
Llama.cppのllama-server を利用するとよいという話を聞きました。どのように設定すればよいか教えてください。

llama-server を利用すると他のPCからアクセスしてLLMの応答を取得できるLLMのAPIサーバーを構築できます。
こちらの記事を参照して、Llama.cppをインストールします。
llama-serverで動作させるLLMのモデルをダウンロードして配置します。今回は、gemma-4-12b-it-qat-q4_0.gguf のモデルを利用しています。
他のマシンからアクセスできるように、ファイアウォールに設定を追加します。
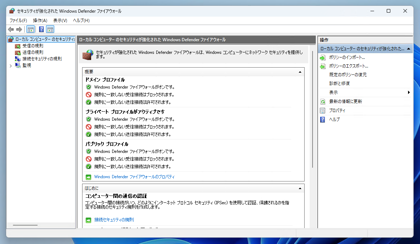
[セキュリティが強化された Windows Defender ファイアウォール] を開きます。下図のウィンドウが表示されます。
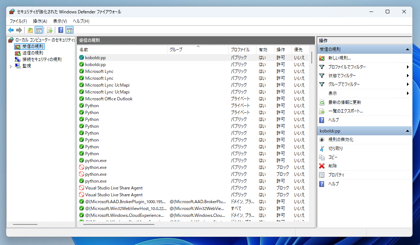
左側のツリービューの[受信の規則]のノードをクリックします。下図の画面が表示されます。
右側の[操作]パネルの[新しい規則]の項目をクリックします。
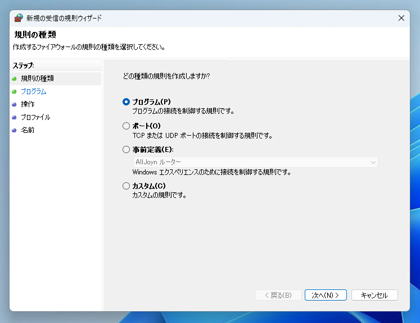
[新規の受信の規則ウィザード]のウィンドウが表示されます。
[規則の種類]の画面が表示さんます。右側の項目は、[プログラム]のラジオボタンをクリックしてチェックします。
[次へ]ボタンをクリックします。
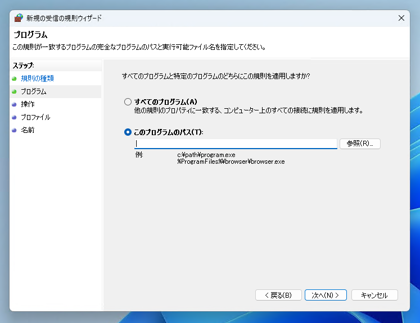
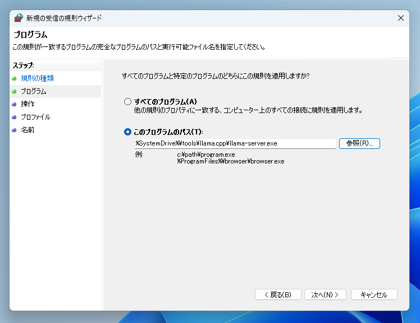
[プログラム]の画面が表示されます。[このプログラムのパス]のラジオボタンをクリックしてチェックを付けます。
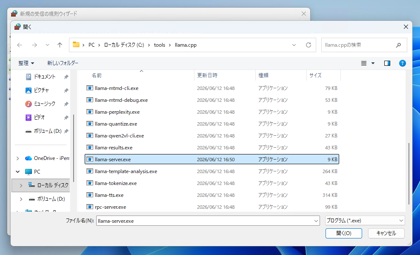
テキストボックスの右側の[参照]ボタンをクリックします。
ファイルを開くダイアログが表示されます。接続を許可する llama-server.exe のプログラムを選択します。
プログラムのパスのテキストボックスに、llama-server.exeのパスが設定できました。[次へ]ボタンをクリックします。
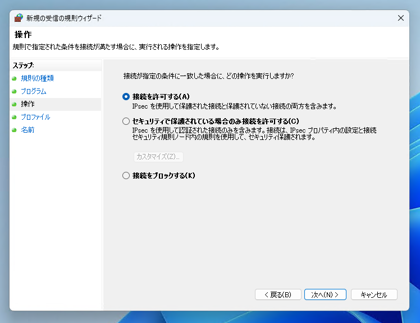
[操作]画面が表示されます。[接続を許可する]のラジオボタンをクリックしてチェックをつけます。[次へ]ボタンをクリックします。
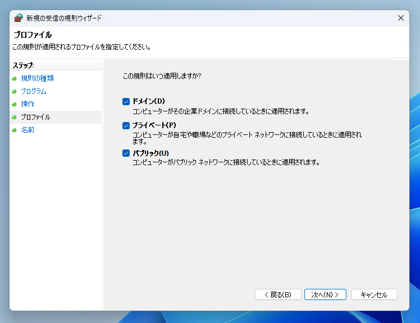
[プロファイル]画面が表示されます。今回は全ての項目にチェックします。[次へ]ボタンをクリックします。
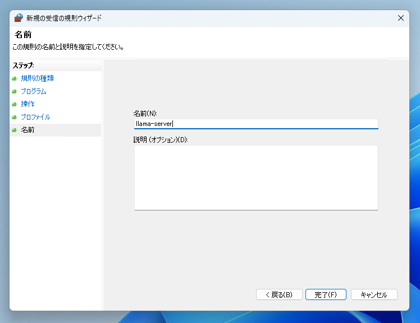
[名前]画面が表示されます。
わかりやすい名前を設定します。今回は "llama-server" とします。[完了]ボタンをクリックします。
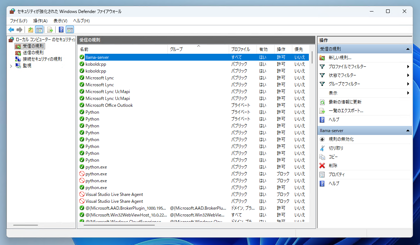
ウィザードのダイアログが閉じられます。受信の規則画面に戻ると、作成した"llama-server"の項目が追加できました。
llama-serverを起動します。次のコマンドを実行します。
llama-server.exe -m (モデルファイルのパス) --host 0.0.0.0 --port 8080
.\llama-server.exe -m C:\tools\llama.cpp\model\gemma-4-12b-it-qat-q4_0.gguf --host 0.0.0.0 --port 8080
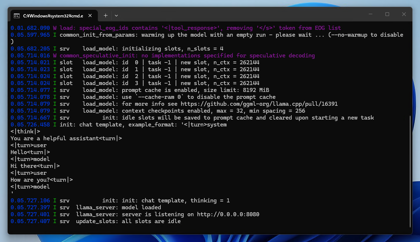
起動できると、以下のメッセージ表示されます。
n.nn.nnn.nnn I srv init: init: chat template, thinking = 1
n.nn.nnn.nnn I srv llama_server: model loaded
n.nn.nnn.nnn I srv llama_server: server is listening on http://0.0.0.0:8080
n.nn.nnn.nnn I srv update_slots: all slots are idle
自身のPCからの場合は、以下のURLでアクセスします。
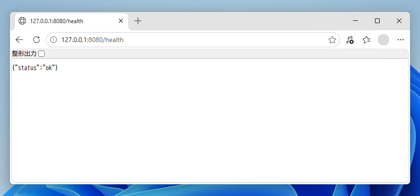
http://127.0.0.1:8080/health
他のPCからの場合は以下のURLとなります。
http://(マシンのIPアドレス):8080/health
正しく起動できていれば、以下が表示されます。
("status":"ok")
チャットで動作確認します。以下のURLにアクセスします。
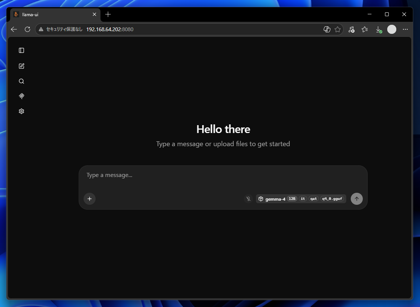
http://127.0.0.1:8080/
他のPCからの場合は以下のURLとなります。
http://(マシンのIPアドレス):8080/
チャットのUI画面が表示されます。
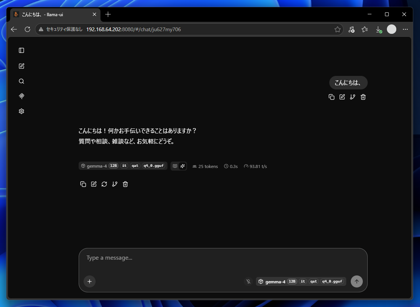
テキストボックスに入力して、送信ボタンをクリックします。返事のメッセージが表示されれば動作しています。
llama-serverを実行できました。