enable_bucket = true を指定することで、Aspect Ratio Bucketing が有効になり正方形以外の画像での学習が実行できます。LoRAの作成 (トレーニング) の手順を紹介します。
こちらの記事では、LoRAの作成手順を紹介しました。
その後、新しいツールが登場したり、Stable Diffusion 1.5 から SDXLへのバージョンアップなどがあり、
LoRAの作成環境も変化しており、2024年9月時点でのLoRAの作成手順をこの記事では紹介します。
Stable Diffusionを導入します。代表的な選択肢として以下があります。
sd-scriptsをインストールします。 インストール手順はこちらの記事を参照してください。
sd-scriptsはLoRAのトレーニングをするプログラムです。また、画像にタグを付与する機能もあります。
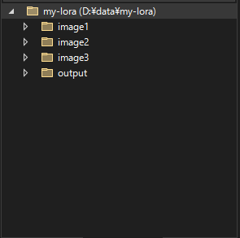
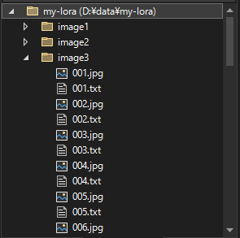
今回は以下のディレクトリ構造で実施します。
LoRAのデータ配置ディレクトリ以下に 学習用画像を保存する、"image1", "image2", "image3" ディレクトリを作成します。
また、出力結果を保存する"output"ディレクトリを作成します。
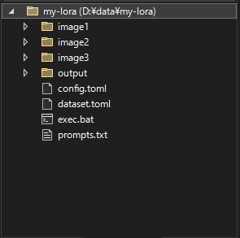
LoRAのデータ配置ディレクトリの直下に、config.toml, dataset.toml, exec.bat, prompt.txt ファイルを配置します。ファイルの内容は後述します。
学習画像は、"image1", "image2", "image3" ディレクトリ内に、"[nnn].png"または"[nnn].jpg"の名称で保存し、画像に対応するタグを "[nnn].txt" ファイル名で保存しています。
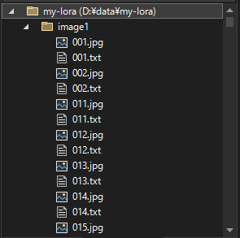
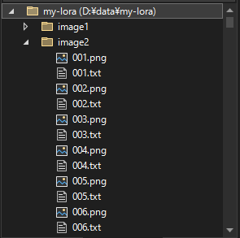
学習したい画像を用意します。
画像を表現するタグを作成します。通常は 001.png という画像ファイルに対して、001.txt という同名のテキストファイルを作成し、
テキストファイル内にタグを記述します。
画像が少ない場合は手動でのタグ付けも可能ですが、画像数が増えると手作業では処理できなくなるため、画像から画像を表すタグを生成します。
sd-scriptsの tag_images_by_wd14_tagger.py を利用して、画像からタグを作成します。
モデルは、2024年9月時点では wd-eva02-large-tagger-v3 が性能が高いモデルです。
手順の詳細はこちらの記事を参照してください。
python finetune/tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-eva02-large-tagger-v3 --batch_size 4 d:\data\my-lora\image1
python finetune/tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-eva02-large-tagger-v3 --batch_size 4 d:\data\my-lora\image2
python finetune/tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-eva02-large-tagger-v3 --batch_size 4 d:\data\my-lora\image3
作成されたタグを整理したり、特定のキャラクターの場合は、トリガーとなるキャラクター名をタグに追加します。
学習データの設定ファイルである dataset.tomlを作成します
以下はSDXLの例です。d:\data\my-lora ディレクトリ内に、image1 image2 image3 の3つのディレクトリに学習画像と
タグのテキストファイルが配置されています。
caption_extensionでタグが記述されているファイルの拡張子を指定します。今回は ".txt" です。
[general]
enable_bucket = true
[[datasets]]
resolution = 1024
batch_size = 12
[[datasets.subsets]]
image_dir = 'D:\data\my-lora\image1'
caption_extension = '.txt'
num_repeats = 1
[[datasets.subsets]]
image_dir = 'D:\data\my-lora\image2'
caption_extension = '.txt'
num_repeats = 1
[[datasets.subsets]]
image_dir = 'D:\data\my-lora\image3'
caption_extension = '.txt'
num_repeats = 1
enable_bucket = true を指定することで、Aspect Ratio Bucketing が有効になり正方形以外の画像での学習が実行できます。resolution = 1024 を resolution = 512 に変更します。sd-scriptsの実行パラメーターを記述した設定ファイルを作成します。
Optimizeerに PagedAdamW8bit を利用する場合です。
[model_arguments]
pretrained_model_name_or_path = "D:\\data\\model\\animagineXLV3_v3Base.safetensors"
[additional_network_arguments]
network_train_unet_only = false
cache_text_encoder_outputs = false
network_module = "networks.lora"
[optimizer_arguments]
optimizer_type = "PagedAdamW8bit"
learning_rate = 1e-4
network_dim = 64
network_alpha = 1
[dataset_arguments]
dataset_config = "D:\\data\\my-lora\\dataset.toml"
cache_latents = true
[training_arguments]
output_dir = "D:\\data\\my-lora\\output"
output_name = "my-lora"
save_every_n_epochs = 1
save_model_as = "safetensors"
max_train_steps = 2000
xformers = true
mixed_precision= "fp16"
save_precision = "fp16"
gradient_checkpointing = true
persistent_data_loader_workers = true
[dreambooth_arguments]
prior_loss_weight = 1.0
[sample_arguments]
sample_every_n_epochs = 2
sample_sampler = "k_euler_a"
sample_prompts = "D:\\data\\my-lora\\prompts.txt"
Optimizeerに Lion を利用する場合です。
[model_arguments]
pretrained_model_name_or_path = "D:\\data\\model\\animagineXLV3_v3Base.safetensors"
[additional_network_arguments]
network_train_unet_only = false
cache_text_encoder_outputs = false
network_module = "networks.lora"
[optimizer_arguments]
optimizer_type = "Lion"
learning_rate = 1e-4
network_dim = 64
network_alpha = 1
#network_args = ["conv_dim=8"] #必要に応じて
[dataset_arguments]
dataset_config = "D:\\data\\my-lora\\dataset.toml"
cache_latents = true
[training_arguments]
output_dir = "D:\\data\\my-lora\\output"
output_name = "my-lora"
save_every_n_epochs = 1
save_model_as = "safetensors"
max_train_steps = 2000
xformers = true
mixed_precision= "fp16"
save_precision = "fp16"
gradient_checkpointing = true
persistent_data_loader_workers = true
[dreambooth_arguments]
prior_loss_weight = 1.0
[sample_arguments]
sample_every_n_epochs = 2
sample_sampler = "k_euler_a"
sample_prompts = "D:\\data\\my-lora\\prompts.txt"
Optimizeerに Prodigy を利用する場合です。
Optimizeerに Prodigy を利用し、ベースモデルをIllustriousにする場合です。
[model_arguments]
pretrained_model_name_or_path = "D:\\data\\model\\Illustrious-XL-v0.1.safetensors"
[additional_network_arguments]
network_train_unet_only = false
cache_text_encoder_outputs = false
network_module = "networks.lora"
[optimizer_arguments]
optimizer_type = "prodigy"
optimizer_args = ["betas=0.9,0.999", "weight_decay=0"]
learning_rate = 1
network_dim = 64
network_alpha = 1
#network_args = ["conv_dim=8"] #必要に応じて
[dataset_arguments]
dataset_config = "D:\\data\\my-lora\\dataset.toml"
cache_latents = true
[training_arguments]
output_dir = "D:\\data\\my-lora\\output"
output_name = "my-lora"
save_every_n_epochs = 1
save_model_as = "safetensors"
max_train_steps = 2000
xformers = true
mixed_precision= "fp16"
save_precision = "fp16"
gradient_checkpointing = true
persistent_data_loader_workers = true
[dreambooth_arguments]
prior_loss_weight = 1.0
[sample_arguments]
sample_every_n_epochs = 2
sample_sampler = "k_euler_a"
sample_prompts = "D:\\data\\my-lora\\prompts.txt"
pretrained_model_name_or_path にはトレーニング元となるモデルを指定します。以下の記述では、"Animagine XL v3.0 Base" を設定しています。
pretrained_model_name_or_path = "D:\\data\\model\\animagineXLV3_v3Base.safetensors"
候補としては以下のモデルがあります。Animagine系のモデルに適用するLoRAの場合は、SDXLかAnimagineをベースモデルにするケースが多いです。
Pony系のモデルに適用するLoRaの場合は、Pony Diffusion v6 XLやAutismMixをベースモデルにするケースが多いです。
後発のIllustrious系のモデルの場合は、Illustrious-XLをベースモデルにするケースが多いです。
ややマイナーですが以下のモデルをベースにしているモデルもあります。AutismMix をベースにしているモデルはそこそこ見かけます。
どのオプティマイザーを利用するかは見解が分かれる点のため、難しいですが、現状では、以下の傾向がありそうです。
どんな状況でもProdigyが良い、Lionが良いという流派もあります。
初めての場合は、強く学習しすぎる傾向がありますが、用意できる画像数が少ない場合、Prodigyは学習結果がはっきり出やすいので、Prodigyから始める方針は良いと思います。
optimizer_type = "PagedAdamW8bit"
学習率を設定します。LoRaの場合は以下の値が使われるケースが多いです。
1e-3 (0.001)
1e-4 (0.0001)
1e-5 (0.00001)
5e-6 (0.000005)
今回は 1e-4 を設定しています。
learning_rate = 1e-4
network_dim の値は今回は64としています。画像数が少ない場合や学習する要素や方向性が少ない場合はnetwork_dimの値を低くしたほうが学習が進みやすいとされています。
network_dimの値については、こちらの記事も参照して下さい。
network_dim = 64
今回は、network_train_unet_only cache_text_encoder_outputs の両方をfalseに設定しており、
テキストエンコーダーを学習しています。SDXLの学習が登場したころはテキストエンコーダーの学習をしないほうが結果が良いとされていましたが、
最近はテキストエンコーダーも学習したほうが良い結果になるとの見解が増えています。
network_train_unet_only = false
cache_text_encoder_outputs = false
テキストエンコーダーの学習をしない場合は、network_train_unet_only cache_text_encoder_outputs の両方をtrueにします。
network_train_unet_only = true
cache_text_encoder_outputs = true
Precisionの設定は、"fp16" としています。"fp16"より、"bf16"のほうが性能は高いため、必要に応じて"bf16"を選択します。
現状多くのモデルでは、fp16を選択しているケースが多い状況です。
mixed_precision= "fp16"
save_precision = "fp16"
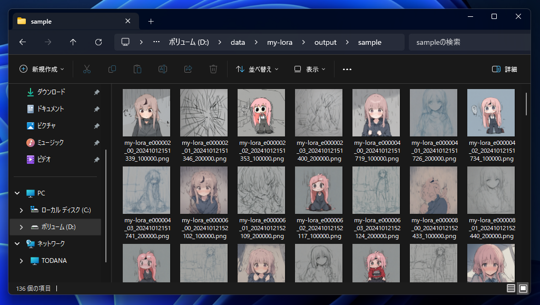
学習の進捗を確認できるように 2エポックごとにサンプル画像を生成して出力する動作にしています。
サンプル画像を生成する際のプロンプトを prompt.txt に記述します。
1girl, upper body, loose lines, rough --w 1024 --h 1024 --d 100000
1girl, upper body, loose lines, rough, sketch, draft --w 1024 --h 1024 --d 200000
1girl, full body, loose lines, rough --w 1024 --h 1024 --d 100000
1girl, full body, loose lines, rough, sketch, draft --w 1024 --h 1024 --d 200000
sd-scriptを起動するバッチファイルを作成します。
accelerate launch --num_cpu_threads_per_process 1 sdxl_train_network.py --config_file=D:\data\my-lora\config.toml
sd-scriptsのディレクトリにカレントディレクトリを変更し仮想環境に切り替えます。
cd (sd-scriptsの配置ディレクトリ)
.\venv\Scripts\Activate
仮想環境に切り替えた後、起動用のバッチファイルを呼び出します。
D:\data\my-lora\exec.bat
sd-scriptsが起動し、トレーニングが始まります。
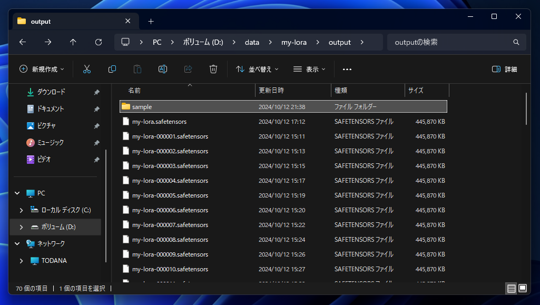
出力ディレクトリの"output"ディレクトリに LoRaのsafetensorsファイルが出力されます。
また、sampleサブディレクトリには、画像生成結果の画像も保存されます。